
大数据解决方案
大数据时代的到来对数据的存储、处理及分析提出了新的挑战, 但总的发展趋势是通过分布式计算来解决 “瓶颈”问题。我们不能依赖提高单个节点性能这种纵向扩展的方式提升系统整体的性能,相反, 我们需要能够通过增加系统内节点的数目这种横向扩展的方式来达到我们的目的。我们将存储、 处理和分析的任务通过分布式的方式分散到系统中各个节点上来加快数据的存储、 处理和分析的速度。在实际的实现上,Google、Amazon、微软和 VMware 这 4 家公司在不同时间陆续推出各自的大数据方案, 在应用领域和赢利模式上,Amazon 和Google 处于跑者地位, 微软和 VMware 紧随其后,此外还有开源的Hadoop 平台。Hadoop 是谷歌大数据平台的开源实现, 由于其开源特性, 越来越多的企业在Hadoop 的基础上对其进行修改以适应自己的需要,如Facebook 根据其业务需求, 底层采用Hadoop 平台进行数据的存储和处理, 并在其上开发了Hive。Facebook 通过Hive实现了例行性报表、 即席查询、 机器学习和数据挖掘算法, 达到了较好的效果。大数据的存储稳定、 高效的存储系统既是系统正常运行的重要保证, 也可以单独作为一项服务提供给用户。5 种方案之中, Amazon 的 S3 和微软的 Blob存储比较类似, Google的GFS则完全不同,VMware 目前仅向虚拟机提供存储服务,Hadoop仿照GFS 开发了HDFS, 是GFS的简化版本。相比GFS, HDFS 缺少了多客户端并发的 Append 模型及快照功能。
大数据的处理
计算服务是所有的大数据解决方案最核心的业务之一, 同时也是用户最常用的服务。Google 和Hadoop提供基于MapReduce 的数据处理, 整个 过 程 对用户而言是透明的。Amazon 的EC2给予用户配置硬件参数的权利, 使得用户可以根据实际的需求动态地改变配置,从而提高效率和节省资源。微软的Azure允许用户在处理数据之前设置部分参数。
VMware 的 vCloud 中提供了DRS 和DPM 技术,可以通过迁移和关闭虚拟机来实现资源优化。表2 是这5 种计算服务的比较。MapReduce 在系统层面解决了大数据分析平台的扩展性和容错性问题,是非关系型数据库的典型代表,因此越来越多的研究人员从性能和易用性方面对MapReduce 进行改进。
1. 多核硬件与图形处理器上的性能改进。
2. 索引技术与连接技术的优化。
3. 调度技术优化。
4. 其他优化技术。
针对MapReduce 易用性的研究成果包括 Yahoo 的 Pig、Microsoft 的LINQ、Hive 等。
山东大学数据分析的几个探索
学术论文成果学科数据可视化探索
我们提出了一个交互系统,用来收集,分析和可视化科研的论文数据,这种方法可用于量化学生和导师的研究成果。系统专门分析了每个作者文章数量和质量的贡献。同时将第一作者的在图形上中显示,其目的是直观地反应论文的详细情况。
我们采用双环可视化方法而不是网络图方法的目的是,观察学生和导师在研究成果中的不同职责,特别是指导学生的导师。同时,学术合作和知识域的变化可以通过可视化的表现形式展现给用户。
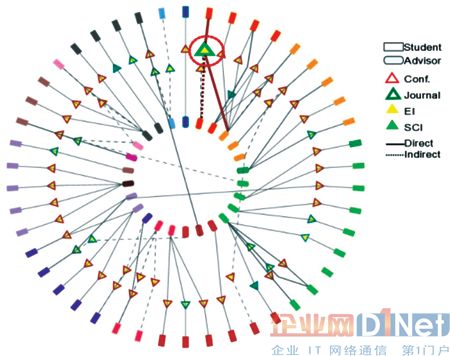
我们开发了在两个同心圆中呈现结果的可视化方法。外圈用不同的颜色将不同级别的学生区分开,内圈用不同的颜色将导师区分开。三角形以及三角形的边框颜色表示了出版的类型(会议或期刊出版),并填充颜色表示不同发表指数(SCI 或EI)的出版物。三角形可以看作是一个箭头指向本文的第一作者,连接到三角形的线表示发表成果的共同作者,实线表示第一作者和第二作者在这个发表成果中的直接贡献,而虚线表示发表成果第一作者和第三作者之间的贡献关系。
我们统计和分析了计算机科学领域2004 至2012 年所有可用的文字类型成果,其中包括作者信息,关键字,摘要,级别和类型。采用指数将EI 和SCI 进行分类。
图1 展示了每年在不同出版物中发表的数量信息。可以看出,该数字波动的年变化,在2008 年和2010 年之间出现明显的热潮,但是之后,开始递减。
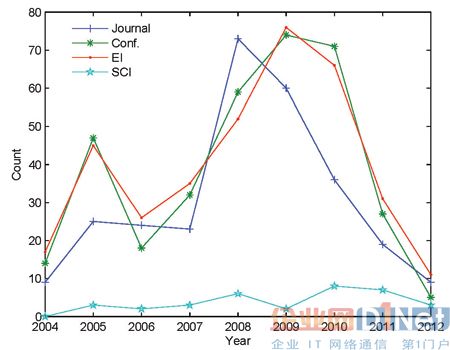
图1 每年在不同出版物中发表的数量信息
此外,刊物的级别可以通过影响因子,反映该杂志近期的文章被引用的平均数。图2 对成果的发表时间进行了评估,通过图表可以清楚地看出,在一年中成果发表水平和数量的情况。例如,2007 年有三个论文的影响因子大于2.0。
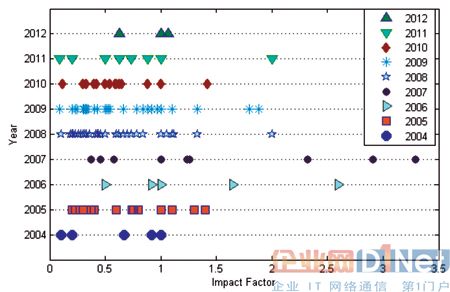
图2 对成果的发表时间进行的评估
图3 表示了导师的研究成果。可以看出,所选中的导师参与了11 篇论文的研究工作,其中包括7 篇会议论文, 4 篇期刊论文,其中四个是SCI 收录。其中,作为第一作者出现一次,作为第二作者出现五次。图4 给出了研究组于2008 年在计算机科学领域的发表成果信息。在外圈上的对象表示学生,内圈的对象表示顾问,对象的颜色区分出他们的研究兴趣是否一致,内外圈上对象会自动调整其位置以避免重叠的出现。在这个交互界面中,发表成果的信息将很容易通过选择三角形进行查询,其详细信息,包括标题,作者,会议或期刊以及其他人的信息将出现在顶部。
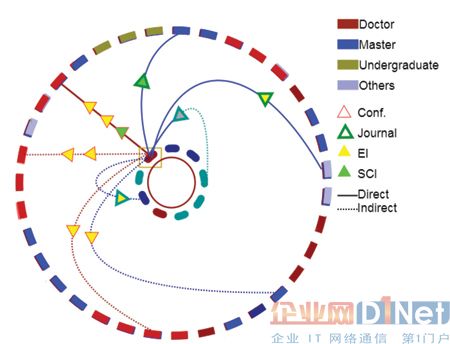
图3 表示了导师的研究成果
招生网站检测与生源数据分析
山东大学本科招生网站是山东大学发布招生信息,录取信息,公布录取结果的重要手段之一,每到招生期间访问人数很大。对于本科招生网站的数据监控和数据分析对于保障招生安全进行,招生数据挖掘和分析有重要的意义。所以每年数据分析的使用有着良好的作用。通过数据挖掘可以分析考生的关注点,考生的活跃时间等有价值的信息。
“大数据”分析做不了什么?
数据可以帮我们解读数字的含义。数据可以辅助我们摆脱直觉和认知的错误。但有些事情是“大数据”不擅长的:
数据不理解社会认知,计算机数据分析擅长的是测量社会交往的“量”而非“质”。数据不了解背景,即便是一部普普通通的小说,数据分析也无法解释其中的思路。
数据扩张太快,关系太复杂,找到有价值信息的难度大。
数据掩盖了价值观念。《“原始数据”只是一种修辞》一书中的要点之一就是,数据从来都不可能是“原始”的,数据总是依照某人的倾向和价值观念而被构建出来的。数据分析的结果看似客观公正,但其实价值选择贯穿了从构建到解读的全过程。
大数据有拿手强项,也有不擅长的领域。我们既需要看到大数据的优点,也要清晰认识到大数据的缺点,解读大数据是一项系统综合工程,与数据所生成的社会背景无法分开。





