|
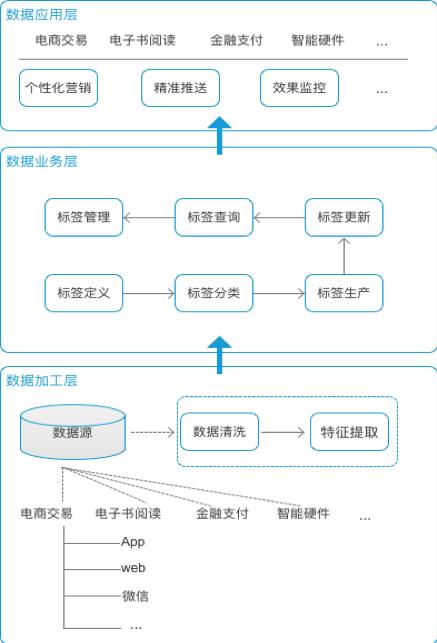
在大数据时代,大数据在呈现出海量化、多样化和价值化变化的同时,也改变了传统IT行业的市场竞争环境、营销策略和服务模式。 如何在ZB级的海量大数据中获取并筛选有价值的信息,是对IT企业的一大挑战。通过构建客户标签,支撑精准营销服务,是应对上述挑战的有效解决方案。 但是怎么设计一个完善的用户标签体系?怎么打标签?打哪些标签?谁来打?怎么使用用户标签创建商业价值? 这些都是产品设计层面需要解决的问题。 掌上医讯一直以来都致力于打造医生的今日头条和智能化的学习平台,通过大数据技术实现医生学习的智能化和个性化,而要构建这样一个学习平台,最基础的就是要建立用户的标签体系。 经过长时间的学习、思考、借鉴和实践,现在已经有了自己的标签构建思路,并且也已经提取出了符合自身业务的标签。我们十分重视用户行为日志的收集,现在已经有了亿万级别的日志大数据,正在搭建大数据处理和标签计算平台,以下是我们整理的建设思想。 标签系统的结构标签系统可以分为三个部分:大数据加工层、大数据服务层和大数据应用层。 每个层面向的用户对象不一样,处理事务有所不同。层级越往下,与业务的耦合度就越小。层级越往上,业务关联性就越强。
大数据加工层大数据加工层收集、清洗和提取大数据。掌上医讯有诸多的学习模块,同时又有网站、APP、小程序等多个产品形式,每个产品模块和产品端都会产生大量的业务大数据和行为大数据,这些大数据极为相似又各不相同,为了搭建完善的用户标签体系,需要尽可能汇总最大范围的大数据。收集了所有大数据之后,需要经过清洗、去重、去无效、去异常等等。 大数据业务层大数据加工层为业务层提供最基础的大数据能力,提供大数据原材料。业务层属于公共资源层,并不归属某个产品或业务线。它主要用来维护整个标签体系,集中在一个地方来进行管理。 在这一层,运营人员和产品能够参与进来,提出业务要求:将原材料进行切割。 主要完成以下核心任务:
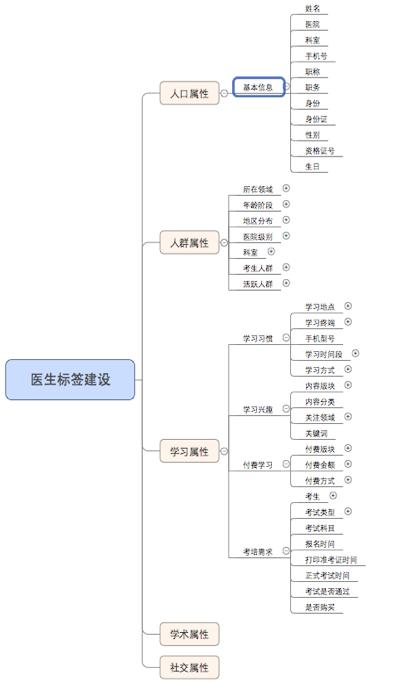
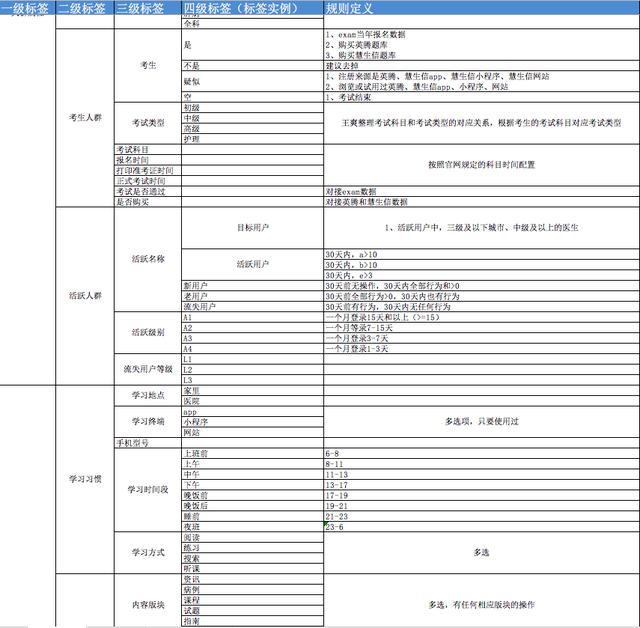
大数据应用层应用层的任务是赋予产品和运营人员标签的工具能力,聚合业务大数据,构建具体的大数据应用场景。 (1)标签的类型 从大数据提取维度来看,标签可分为:事实标签、模型标签和预测标签。 (2)事实标签 从生产系统获取大数据,定性或定量描述用户的自然属性、产品属性、消费属性、资源属性等,以及根据工作人员经验积累的业务规则进行筛选、分析生产的标签,如是否活跃用户、是否是考生等。 (3)模型标签 对用户属性及行为等属性的抽象和聚类,通过剖析用户的基础大数据为用户贴上相应的总结概括性标签及指数,标签代表用户的兴趣、偏好、需求等,指数代表用户的兴趣程度、需求程度、购买概率等。 (4)预测标签 基于用户的属性、行为、信令、位置和特征,挖掘用户潜在需求,针对这些潜在需求配合营销策略、规则进行打标,实现营销适时、适机、适景推送给用户。 从大数据的时效性来看,标签可分为:静态属性标签和动态属性标签。 (5)静态属性标签 长期甚至永远都不会发生改变。比如性别,出生日期,这些大数据都是既定的事实,几乎不会改变。 (6)动态属性标签 存在有效期,需要定期地更新,保证标签的有效性。比如:用户的购买力,用户的活跃情况。 标签的定义给用户打标签,建立用户画像,最终都是为了去应用,所以我们要站在应用场景上去定义用户的标签体系,每个标签都有最终的用途。比如:我们做考试培训服务,我们需要建立“是否考生”的标签。 另外,不同的行业他们的用户特征也是有显著区别的,比如:医生用户相比普通用户来说,就多了像“科室”、“职称”、“所在医院等级”等特殊含义的标签。 而标签是有层级关系的,既是为了管理,更好的理解,又是为了控制粗细力度,方便最终的应用。标签深度一般控制在四级比较合适,到了第四级就是具体的标签实例。 我们根据公司的业务首先划分了人口属性、行为属性、用户分类和商业属性四个大的分类,下面又分了上网习惯、学习惯、人群属性、消费能力、消费习惯等分类,最末级精确到用户的活跃等级、阅读来源、考试偏好等具体的标签。
标签的维护每个标签都不会凭空产生的,也不会一成不变,更不会凭空消失。标签的维护需要生成规则,需要定义权重,需要更新策略。 生成规则 如第一部分所说,标签分为事实标签,模型标签和预测标签三大类。对于这三类的标签,生成规则的难度和复杂性也是逐级递增的。事实标签只需要考虑从什么地方提取即可,它即包含明确的标签定义,又包含无法穷举的标签集,比如:关注的病种。 而模型标签需要进行大数据的关联和逻辑关系的设计,通过一定的模型对大数据进行计算得来。而预测标签相对就非常的复杂,无法从原始大数据提取标签,标签的生成准确度就太依赖我们大数据分析和人工智能技术的应用。
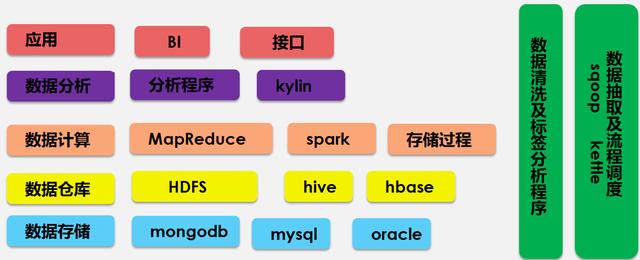
定义权重 一个标签会在多个场景下出现,比如:一个疾病标签,它极可能在浏览过程中生成,也有可能在搜索场景下产生,但是对于这两个场景所对应的同一个标签,他们的权重是不同的。浏览相比搜索,权重要小得多,因为搜索的主动需求更大。 更新策略 上文我们从大数据的时效性上对标签分为静态属性标签和动态属性标签,对于静态属性标签的处理相对比较简单,就不停的累加即可。但是对于动态属性标签,需要对过期标签进行降权甚至删除处理,比如:医生考试前和考试后,会影响“是否考生”这个标签的,这就需要制定更新策略。 标签建设的技术架构标签体系的建设涉及很多环节,大数据量也十分巨大,需要有一个健壮且高效的技术架构来支持大数据的存储及计算,掌上医讯采用了sql大数据库和no-sql大数据库来满足结构化大数据和非结构化大数据的存储。 使用hadoop的分布式存储技术及hive和hbase组件作为大数据仓库,使用MapReduce和spark分布式计算来提高计算速度,使用kylin进行多维分析,通过BI工具和接口对外提供应用,使用sqoop和kettle进行大数据的抽取及流程的调用。
更多的应用场景用户标签建立已经基本应用在掌上医讯的内容智能推荐的学习场景中,但随着标签的完善以及智能化处理的提升,这套标签体系将有更广阔的应用场景。 (1)智能化学习场景的构建 通过用户学习需求的标签的分析进行用户分群,针对不同的用户群在APP的功能和内容上进行个性化展示,满足不同学习需求的用户个性化的学习服务。 (2)精准营销推广的建立 更细粒度的对用户进行筛选,同时能够精准预测可能存在的目标用户进行推广,从而扩大医生覆盖,提升推广的转化率。 (3)KOL用户画像的描绘 基于该标签模型,增加对外部大数据的采集分析,更加完整的生成医生360度的用户画像,帮助企业寻找潜在的KOL用户,实现用户洞察,辅助市场决策。 标签的建设是一个看似高大上,其实很繁琐、纠结的过程,需要对业务抽丝剥茧,还要应对运营需求的各种变化,不过对公司发展的影响也是深远的。 |