
近两年,大数据概念越来越火,很多用户都开始逐渐应用大数据技术挖数据金矿。但是,对于传统的工业生产或者科研行业,从事研究的人未必对计算机的算法编程非常熟悉,他们如何利用大数据技术做这方面的工作呢?今天多数的大数据方案都是依托Hadoop技术来做结构化和非结构化数据处理,但是在这之前,收集到数据后,如何对数据进行整合和清洗,数据探索及处理,这个过程所耗费的时间往往是最后技术实现的几倍。另外,又如何把自己的Hadoop算法部署到实际的生产环境当中去,这也需要花费专业的技术人员来做。
MathWorks公司的MATLAB软件在科研和工业生产上的用户非常多,他们最近也提出针对大数据的解决方案,针对前面的问题,他们更多的从生态开发环境来考虑,把大数据分析处理做成了一个完整的流程,然后利用诸多工具和技术,解决用户实际的问题。下面我们就来看看他们关于大数据分析的流程,来自MathWorks公司的高级应用工程师陈建平对记者做了详细介绍。
首先基本上把整个流程分成四步:
第一步是怎么去获取数据;
第二步是怎么从这个数据中得到一些基本的信息,所谓数据清洗跟一些数据的一些基本信息的提取。
第三步是从数据中获得哪些知识,要从数据中抓取有用的知识,这其实是真正的大数据的学习的过程。这其中会涉及很多技术,比如机器学习,数据挖掘等。
最后的问题是用这个知识怎么去做一个模型,能够对未来进行预测,这是一个大数据分析的结果。
第一个部分,怎么去获取数据。获取数据,MathWorks最大的一个产品就是MATLAB,但是实际上MATLAB这个技术给大家发展了80多个相关的工具。从数据采集上来说,基本上从四个方面去支持这个数据的来源。第一个就是数据库的访问,数据库访问包括传统的通用的数据库,也包括一些分布式的文件系统,当然也包括非结构化数据库。还有Financial data(金融数据),多数是通过网络的方式去抓。数据库访问是数据的第一种介入的方式,这也是很多的厂商已经存好的一种格式,所以这个格式会比较的干净。第二种数据的格式是文件系统的这个读写,有多种方式可以让你的读写变得非常的高效。第三种是硬件接入,比如标准的图像抓取和实验室仪器的数据,还有一些数据采集卡,从硬件的角度来获取这个数据。另外一个就是如果仪器做成比较标准的接口的话,也可以直接从你的仪器接口去抓取,通过一些专用的协议直接去抓数据。所以,数据来源上基本上来说覆盖了绝大部分的这个数据来源。
第二个步骤就是有关这个数据的一些组织跟基础的一些分析,基本上通过一些统计的手段。MathWorks有一些统计机器学习工具箱,这是一个非常传统的工具箱,里面嵌了大量的统计相关的函数,也有一些可视化的面板,可以直接给你快速地做一些快速的数据分析,你可以从数据得到你想得到的这么一些基础的数据的理解。那可视化当然是MathWorks一个传统的产业,这是MATLAB上面基本上很多人之所以使用MATLAB的一个最原始的出发的一个点,其实也是为了可视化。
第三步就是数据处理,比如去掉一些没用的数据,数据滤波等前期处理。最后就是从数据的学习角度来说,在统计工具箱里面扩展。当然还有专门的做神经网络跟深度学习的一个工具箱,所以你可以从你的前期的数据结果里很快、快速地切入到MATLAB的核心学习之中去。
最后一个流程是发布,MathWorks现在在MATLAB中可以直接去产生对应的报告文件,这是可以自动产生的一个分析报告。你可以去把你的程序直接打包成APP,这个做法基本上你可以把你MATLAB写的东西直接把它做成APP。那你也可以把它做一些,切入到信用的系统之中去,也可以去产生对应的这个C代码或者是可以打包成JAVA的代码跟多端的部署的代码。所以,这个基本上就一键式的操作,你不需要特别专业的背景。
实际上MATLAB现在覆盖从最主的数据获取、数据的组织基础的这个探索和分析。那通过这些高端的机器学习的方法进行大数据的一些学习,最后搭成模型之后,你可以快速地把它嵌入到生产环境当中去。
除了这个完整的流程外,MATLAB针对不同的数据规模和数据类型,也提供了不同的大数据分析技术。陈建平介绍说:“MATLAB针对不同的数据规模其实有不同的处理的专门针对这些问题的这个处理手段,我们把这个数据划分成两类,一类叫可以分割的,一类是不可以分割的。可以分割的就分割成简单的数据,然后用一种办法来处理。不能简单分割的,又把它分成两类,第一类问题是我们可以把它夹杂在内存中间进行操作的这个数据,或者放在集群的内存总和中进行操作。另外一个,甚至你集群的内存都没法处理的条件下,你可以用MapReduce的手段来处理。所以,从这个数据的复杂度角度来说,我们提供不同的数据类型,我们都进行了支持。”
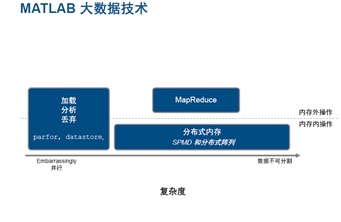
第一类问题现在是有一套自动化的方法来做的,比如专门的并行化的方法,叫Pafor,这个数据很简单,就是自动并行化的一种手段。
第二类问题非常复杂,它涉及到超算的范围,所以现在这个MATLAB也能做。只是这个数据的类型特别复杂,单机无法处理,但是集群可以处理,你不需要做特别复杂的规模的编程,对我们来说很简单。
所以,你只要做的事情就是我们调用对应的这个函数就可以了,所以正常的就跟单机做这个数据处理的手段是差不多的。所以很容易扩展到这个集群之中去。我们对应的工具箱你可以使用一些,我们叫丰富的计算的Model Based System的这么一套工具去做这个事情,可以嵌入到你的集群中做这个事儿。
第三类数据其实就是大家现在最关注的数据,数据大到一定的规模,必须通过MapReduce这种方式来做。我们也提供了MapReduce的一个实现,在这里面你需要提供两个东西,第一个datastore,你的数据是什么东西?第二个,你需要提供MAP函数,就是把一个数据从一个点,一个数据变化到另外一个点上。所以,你提供一个MAP函数,再提供一个,后面这个提供一个reduce函数,通过调用reduce,完了。你不需要额外的早晚地去使,对你来说,你只要写一个MAP函数,写一个reduce函数,然后放到MapReduce函数的里面,你就可以得到一个MapReduce的计算机了。你运行这个程序,做好MapReduce它就可以做这个事情了。所以,这是很容易的跟Hadoop的环境进行集成到一起的一种方式,你甚至可以看一眼这个MapReduce的这个数据。
最后,怎么把这个问题部署到这个Hadoop环境中去,部署非常简单,MATLAB有一套自动的部署的工具,有个按鼠标点击的自动部署工具,你可以看一眼大概怎么做的。比如说你要做一个Hadoop的这个应用的话,你要MATLAB有很多叫app的东西,就是很多应用程序。你要做的事情是你打开这个应用程序,把你的函数,把这个MAP函数把它填进去,把reduce函数填进去,一点,你就会产生一个EXE的程序。所以,你不需要知道怎么去打包,对你来说就是打开程序,把MAP函数放进去,或reduce函数放进去,一点打包,你会出来一个EXE的程序。
所以,这就是个发挥的过程,那这个EXE的程序当然MATLAB也支持可以做EXE,也可以做,你可以在里面设置你不同的目标,EXE是一种手段。那你当然可以是做成一个JAVA的包,你可以把这个程序打成一个JAVA的包,可能被其他程序二次开发,你可以做成个dotnet的包,也可以被用作二次开发。因为基本上这个流程就是非常地简单,你需要写好你的MATLAB的程序,打开这个部署工具,然后把你的函数放到里面,点打包就会产生一个EXE程序。产生了EXE程序是我们这个打包发布出去,打包发布之后的程序,这完全可以脱离MATLAB环境来运行,你可以脱离MATLAB环境,你不再需要运行的机器上安装MATLAB。然后这个时候它会把运算的过程中,把这个计算的要求自动发到你指定的环境之中去,进行计算,算完了之后把结果自动取回来,所以这个都是自动化的,所以你不需要知道很多如何进行数据收发,也不需要知道怎么去跟Hadoop环境进行交互。你要做的事情就是管好你的鼠标就OK了。这是有关部署的情况。
不管从大数据的整体流程上还是从数据分析和处理的相关技术方面,MATLAB的相关工具为用户提供了方便的工具和开发环境,用户不用去过多关注算法与函数的问题,从而节省了很多时间,让大数据分析与应用开发成为一件简单轻松的问题。





