
当前无论是传统企业还是互联网公司对大数据实时分析和处理的要求越来越高,数据越实时价值越大,面向毫秒~秒级的实时大数据计算场景,Spark和Flink各有所长。CarbonData是一种高性能大数据存储方案,已在20+企业生产环境上部署应用,其中最大的单一集群数据规模达到几万亿。
为帮助开发者更深入的了解这三个大数据开源技术及其实际应用场景,9月8日,InfoQ联合华为云举办了一场实时大数据Meetup,集结了来自Databricks、华为及美团点评的大咖级嘉宾前来分享。
本文整理了其中的部分精彩内容,同时,作为本次活动的承办方,InfoQ整理上传了所有讲师的演讲PPT,感兴趣的同学可以下载讲师PPT获取完整资料 。
Spark Structured Streaming特性介绍 (讲师PPT下载)
作为Spark Structured Streaming最核心的开发人员、Databricks工程师,Tathagata Das(以下简称“TD”)在开场演讲中介绍了Structured Streaming的基本概念,及其在存储、自动流化、容错、性能等方面的特性,在事件时间的处理机制,最后带来了一些实际应用场景。
首先,TD对流处理所面对的问题和概念做了清晰的讲解。TD提到,因为流处理具有如下显著的复杂性特征,所以很难建立非常健壮的处理过程:
• 一是数据有各种不同格式(Jason、Avro、二进制)、脏数据、不及时且无序;
• 二是复杂的加载过程,基于事件时间的过程需要支持交互查询,和机器学习组合使用;
• 三是不同的存储系统和格式(SQL、NoSQL、Parquet等),要考虑如何容错。
因为可以运行在Spark SQL引擎上,Spark Structured Streaming天然拥有较好的性能、良好的扩展性及容错性等Spark优势。除此之外,它还具备丰富、统一、高层次的API,因此便于处理复杂的数据和工作流。再加上,无论是Spark自身,还是其集成的多个存储系统,都有丰富的生态圈。这些优势也让Spark Structured Streaming得到更多的发展和使用。
流的定义是一种无限表(unbounded table),把数据流中的新数据追加在这张无限表中,而它的查询过程可以拆解为几个步骤,例如可以从Kafka读取JSON数据,解析JSON数据,存入结构化Parquet表中,并确保端到端的容错机制。其中的特性包括:
• 支持多种消息队列,比如Files/Kafka/Kinesis等。
• 可以用join(), union()连接多个不同类型的数据源。
• 返回一个DataFrame,它具有一个无限表的结构。
• 你可以按需选择SQL(BI分析)、DataFrame(数据科学家分析)、DataSet(数据引擎),它们有几乎一样的语义和性能。
• 把Kafka的JSON结构的记录转换成String,生成嵌套列,利用了很多优化过的处理函数来完成这个动作,例如from_json(),也允许各种自定义函数协助处理,例如Lambdas, flatMap。
• 在Sink步骤中可以写入外部存储系统,例如Parquet。在Kafka sink中,支持foreach来对输出数据做任何处理,支持事务和exactly-once方式。
• 支持固定时间间隔的微批次处理,具备微批次处理的高性能性,支持低延迟的连续处理(Spark 2.3),支持检查点机制(check point)。
• 秒级处理来自Kafka的结构化源数据,可以充分为查询做好准备。
Spark SQL把批次查询转化为一系列增量执行计划,从而可以分批次地操作数据。
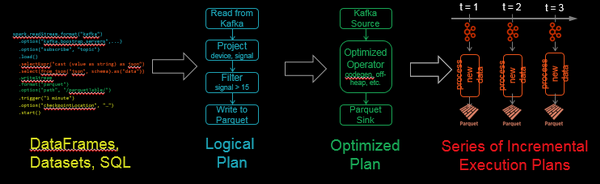
在容错机制上,Structured Streaming采取检查点机制,把进度offset写入stable的存储中,用JSON的方式保存支持向下兼容,允许从任何错误点(例如自动增加一个过滤来处理中断的数据)进行恢复。这样确保了端到端数据的exactly-once。
在性能上,Structured Streaming重用了Spark SQL优化器和Tungsten引擎,而且成本降低了3倍!!更多的信息可以参考作者的blog。
Structured Streaming隔离处理逻辑采用的是可配置化的方式(比如定制JSON的输入数据格式),执行方式是批处理还是流查询很容易识别。同时TD还比较了批处理、微批次-流处理、持续流处理三种模式的延迟性、吞吐性和资源分配情况。
在时间窗口的支持上,Structured Streaming支持基于事件时间(event-time)的聚合,这样更容易了解每隔一段时间发生的事情。同时也支持各种用户定义聚合函数(User Defined Aggregate Function,UDAF)。另外,Structured Streaming可通过不同触发器间分布式存储的状态来进行聚合,状态被存储在内存中,归档采用HDFS的Write Ahead Log (WAL)机制。当然,Structured Streaming还可自动处理过时的数据,更新旧的保存状态。因为历史状态记录可能无限增长,这会带来一些性能问题,为了限制状态记录的大小,Spark使用水印(watermarking)来删除不再更新的旧的聚合数据。允许支持自定义状态函数,比如事件或处理时间的超时,同时支持Scala和Java。
TD在演讲中也具体举例了流处理的应用情况。在苹果的信息安全平台中,每秒将产生有百万级事件,Structured Streaming可以用来做缺陷检测,下图是该平台架构:
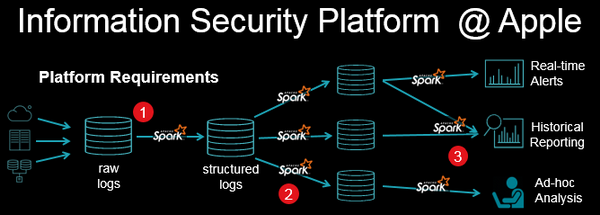
在该架构中,一是可以把任意原始日志通过ETL加载到结构化日志库中,通过批次控制可很快进行灾难恢复;二是可以连接很多其它的数据信息(DHCP session,缓慢变化的数据);三是提供了多种混合工作方式:实时警告、历史报告、ad-hoc分析、统一的API允许支持各种分析(例如实时报警系统)等,支持快速部署。四是达到了百万事件秒级处理性能。
华为大数据架构师蔡强在以CarbonData为主题的演讲中主要介绍了企业对数据应用的挑战、存储产品的选型决策,并深入讲解了CarbonData的原理及应用,以及对未来的规划等。
企业中包含多种数据应用,从商业智能、批处理到机器学习,数据增长快速、数据结构复杂的特征越来越明显。在应用集成上,需要也越来越多,包括支持SQL的标准语法、JDBC和ODBC接口、灵活的动态查询、OLAP分析等。
针对当前大数据领域分析场景需求各异而导致的存储冗余问题,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持支持快速过滤查找和各种大数据离线分析和实时分析,并通过多级索引、字典编码、预聚合、动态Partition、实时数据查询等特性提升了IO扫描和计算性能,实现万亿数据分析秒级响应。蔡强在演讲中对CarbonData的设计思路做了详细讲解。
• 在数据统一存储上:通过数据共享减少孤岛和冗余,支持多种业务场景以产生更大价值。
• 大集群:区别于以往的单机系统,用户希望新的大数据存储方案能应对日益增多的数据,随时可以通过增加资源的方式横向扩展,无限扩容。
• 易集成:提供标准接口,新的大数据方案与企业已采购的工具和IT系统要能无缝集成,支撑老业务快速迁移。另外要与大数据生态中的各种软件能无缝集成。
• 高性能:计算与存储分离,支持从GB到PB大规模数据,十万亿数据秒级响应。
• 开放生态:与大数据生态无缝集成,充分利用云存储和Hadoop集群的优势。
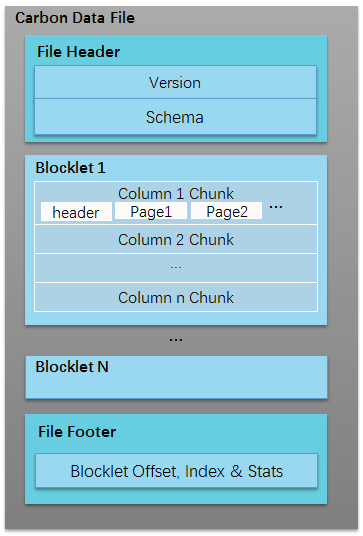
数据布局如下图,CarbonData用一个HDFS文件构成一个Block,包含若干Blocklet作为文件内的列存数据块,File Header/Fille Footer提供元数据信息,内置Blocklet索引以及Blocklet级和Page级的统计信息,压缩编码采用RLE、自适应编码、Snappy/Zstd压缩,数据类型支持所有基础和复杂类型:
Carbon表支持索引,支持Segment级(注:一个批次数据导入为一个segment)的读写和数据灵活管理,如按segment进行数据老化和查询等,文件布局如下:
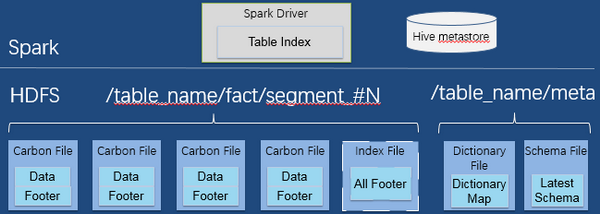
• Spark Driver将集中式的索引存在内存中,根据索引快速过滤数据,Hive metastore存储表的元数据(表的信息等)。
• 一次Load/Insert对应生成一个Segment, 一个Segment包含多个Shard, 一个Shard就是一台机器上导入的多个数据文件和一个索引文件组成。每个Segment 包含数据和元数据(CarbonData File和Index文件),不同的Segment可以有不同的文件格式,支持更多其他格式(CSV, Parquet),采用增量的数据管理方式,处理比分区管理的速度快很多。
查询时会将filter和projection下推到DataMap(数据地图)。它的执行模型如下:
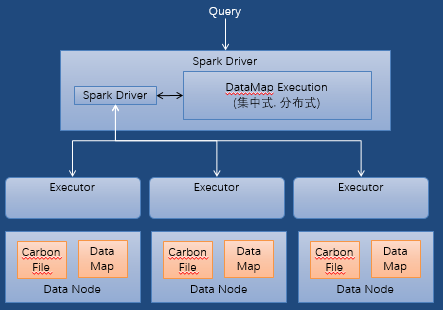
• 主要包括Index DataMap和MV DataMap两种不同DataMap,三级Index索引架构减少了Spark Task数和磁盘IO,MV可以进行预汇聚和join的操作,用数据入库时间换取查询时间。
• DataMap根据实际数据量大小选择集中式或者分布式存储,以避免大内存问题。
• DataMap支持内存或磁盘的存储方式。
最后,蔡强也分析了CarbonData的具体使用和未来计划。
在使用上,CarbonData提供了非常丰富的功能特性,用户可权衡入库时间、索引粒度和查询性能,增量入库等方面来灵活设置。表操作与SparkSQL深度集成,支持高检测功能的可配置Table Properties。语法和API保持SparkSQL一致,支持并发导入、更新、合并和查询。DataMap类似一张视图表,可用于加速Carbon表查询,通过datamap_provider支持Bloomfilter、Pre-aggregate、MV三种类型的地图。流式入库与Structured Streaming集成,实现准实时分析。支持同时查询实时数据和历史数据,支持预聚合并自动刷新,聚合查询会先检查聚合操作,从而取得数据返回客户端。准实时查询,提供了Stream SQL标准接口,建立临时的Source表和Sink表。支持类似Structured Streaming(结构化流)的逻辑语句和调度作业。
CarbonData从2016年进入孵化器到2017年毕业,一共发布了10多个稳定的版本,今年9月份将会迎来1.5.0版的发布。1.5.0将支持Spark File Format,增强对S3上数据的支持,支持Spark2.3和Hadoop3.1以及复杂类型的支持。而1.5.1主要会对MV支持增量的加载,增强对DataMap的选择,以及增强了对Presto的支持。





